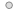CONTENT ANALYSIS AND TEXT-MINING TOOL FOR STATA
Stata is a complete, integrated statistical software package created by StataCorp LP.
It provides a wide range of statistical analysis, data management, and graphics. The latest versions of Stata added many new features, including a long string data type allowing one to store along with numerical and categorical data, documents up to 2 billion characters. One could thus create a statistical database with journal abstracts, news transcripts, patents, incident reports, customer feedback, interviews, and so on.
WordStat for Stata was created to allow users of Stata 13 to Stata 18 running under Windows, to apply text analytics techniques on any string variables stored in a Stata data file. WordStat combines natural language processing, content analysis, and statistical techniques to quickly extract topics, patterns, and relationships in large amounts of text. It can process millions of words in seconds and compare extracted themes across any other numerical, categorical, or date variables in the Stata file.
What it is used for?
WordStat can be used by anyone who needs to quickly extract and analyze information stored in Stata text variables. It may be used for:
• Directly import text and quantitative data from social media, online survey platforms, reference management tools
• Content analysis of open-ended responses, interview or focus group transcripts
• Business intelligence and competitive web sites analysis
• Information extraction and knowledge discovery from incident reports, customer complaints
• Content analysis of news coverage or scientific literature (scientometrics or bibliometrics studies)
• Automatic tagging and classification of documents
• Fraud detection, authorship attribution, patent analysis
• Taxonomy development and validation
WORDSTAT FOR STATA KEY FEATURES:
EXPLORATORY TEXT MINING
Integrated exploratory text mining and visualization tools such as clustering, multidimensional scaling, proximity plots, and more, to quickly extract themes and automatically identify patterns.
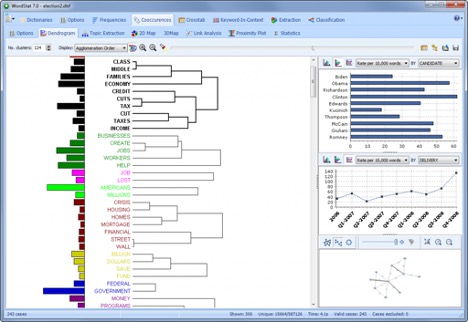
TOPIC MODELING
Get a quick overview of the most salient topics from large text collections. A side panel allows one to compare the frequency of specific topics across other variables using bar charts or line charts.
CATEGORIZATION DICTIONARIES
Use existing or create custom dictionaries composed of words, word patterns, phrases and proximity rules. Get computer assistance for building taxonomies with phrase and named-entity extraction, misspelling replacements, integrated thesaurus, etc..
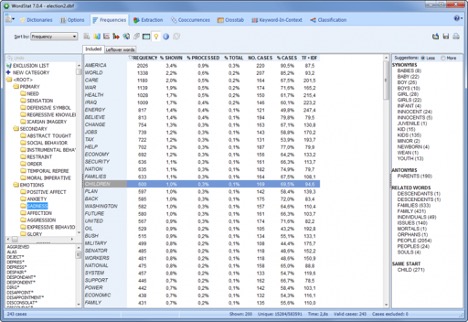
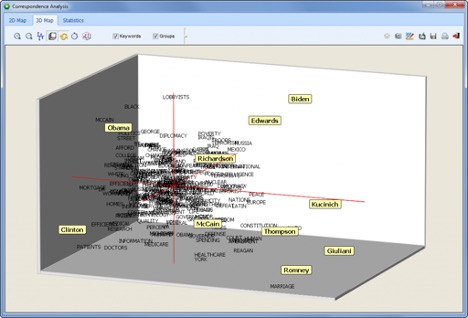
COMPARATIVE ANALYSIS
Explore relationships between unstructured text and structured data with statistical and graphical tools (correspondence analysis, heatmaps, bubble charts, etc.).
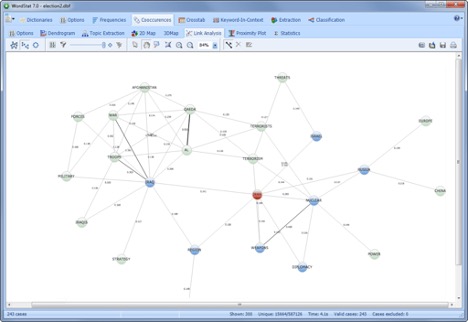
LINK ANALYSIS
Explore relationships among words or extracted concepts using force-based graphs, multidimensional scaling or circular graphs. Retrieve text segments associated with specific connections.
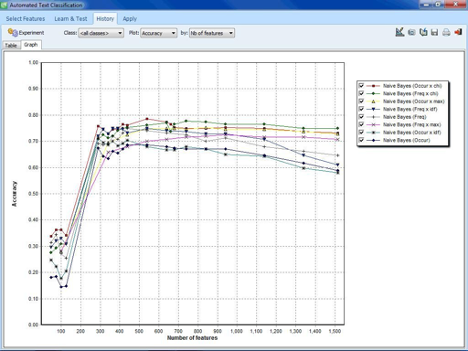
MACHINE LEARNING
Develop automatic document classification models by using Naive Bayes and K-Nearest Neighbors. Classification models may then be saved on disk and reapplied on new data.
CHARTING
Illustrate patterns and explore complex phenomena with interactive visualization tools such as bar charts, line charts, heatmaps, word clouds, bubble charts, MDS plots, etc.. Copy and paste charts or saved them to disk in bmp, jpg, or png file formats.
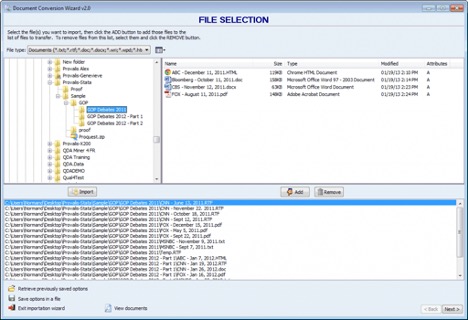
DOCUMENT CONVERSION WIZARD
The Document conversion wizard allows one to easily import into a new Stata .dta file, documents stored in various file formats (.DOC, HTML, PDF, TXT) and automatically extract numeric and alphanumeric values from structured documents